Composite Design Pattern With Real World Example In Java
Composite Pattern or Composite Design Pattern: Learn Composite Design Pattern with Real World Example by creating an HTML parser
In this tutorial we’ll be learning Component Design Pattern. We’ll be creating a very simple HTML viewer or parser while learning Component Design Pattern. Then using Command Design Pattern we’ll address the design issues. In the second part of this document we will look into a real world example of how the two very popular libraries, HtmlUnit and JSoup, use it. Then we will look into the use case scenarios for which the Composite Design Pattern is a good fit.
In an HTML document there are multiple HTML elements. These elements have tags or types, attributes, etc. For example, <p> or <table>.
The web developer creates an HTML document that contains those HTML elements. Then the web browser reads the HTML content and paints the output on the page. A very simple HTML element can be represented using the following class:
class HTMLElement {
// This field contains the text body of the HTML element.
private String text;
// This field represents the HTML type, like, tr or td.
private String type;
public String getText() {
return text;
}
public void setText(String text) {
this.text = text;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
}
This HTMLElement contains two fields:
- Text: This will keep the textual data of the field.
- Type: The actual type of the HTML element.
For example, the following HTML element:
<p>
This world is a very beautiful place.
</p>
can be converted to an HTMLElement object through the following code:
HTMLElement paragraph = new HTMLElement();
paragraph.setType("p");
paragraph.setText("This world is a very beautiful place.");
And then we can create a HTML page class that’ll hold all these HTML elements:
class HTMLPage {
private List<HTMLElement> elements = new ArrayList<>();
public void addElement(HTMLElement element) {
elements.add(element);
}
public Iterator<HTMLElement> iterator() {
return elements.iterator();
}
}
This Page class has a list of HTML elements. It also returns an iterator if the client wants to go through the HTML
elements. Once the iterator is available then all the elements can be accessed and the text() method can be called to
display the content for that HTML element. For example, the following HTML content:
<p>
This world is a very beautiful place.
</p>
<div>
Can it be made any more beautiful?
</div>
can be created like:
// <p>
// This world is a very beautiful place.
// </p>
HTMLElement paragraph = new HTMLElement();
paragraph.setType("p");
paragraph.setText("This world is a very beautiful place.");
// <div>
// Can it be made any more beautiful?
// </div>
HTMLElement div = new HTMLElement();
paragraph.setType("div");
paragraph.setText("Can it be made any more beautiful?");
page.addElement(paragraph);
page.addElement(div);
Iterator<HTMLElement> elementIterator = page.iterator();
while (elementIterator.hasNext()) {
System.out.println(elementIteratir.next().text());
}
Our HTML creator is doing a fine job. But can it handle the following HTML?
<div>
<div>
<p>Paragraph 1</p>
<p>Paragraph 2</p>
<p>Paragraph 3</p>
</div>
<div>
<div>
<p>Paragraph 4</p>
<p>Paragraph 5</p>
<p>Paragraph 6</p>
</div>
<p>Paragraph 7</p>
<p>Paragraph 8</p>
</div>
</div>
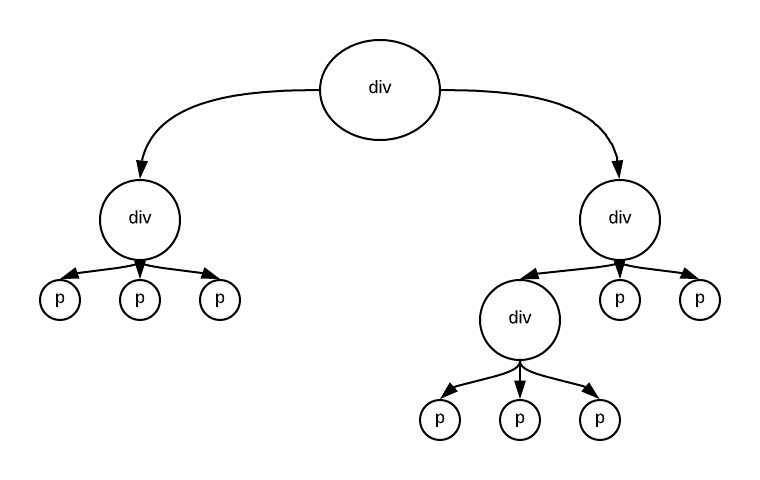
Well it cannot anymore. Why? Because every HTML element is behaving like an HTML Page in itself. An HTML element can have multiple children, or it may have no children.
This structure is now converted to an HTML tree(or DOM tree) with the HTML elements having no children becoming the leaf elements of the tree.
One point to note here it that the output of the text() method for:
<div>
<p>Paragraph 1</p>
<p>Paragraph 2</p>
<p>Paragraph 3</p>
</div>
would be
Paragraph 1
Paragraph 2
Paragraph 3
Basically, the text of a non leaf element is equal to the text of all the leaf elements present in that HTML element
combined. So, the text() method is now going to delegate to all its child nodes.
So be it a Leaf element, or a composite element, text method should be there, but their handling would be different.
This means we’re treating them uniformly and to do that we’ve to create an abstraction on top of it. Using that
abstraction the client will be able to treat both the objects uniformly. The client will not care if the object is a
composite element or a leaf node.
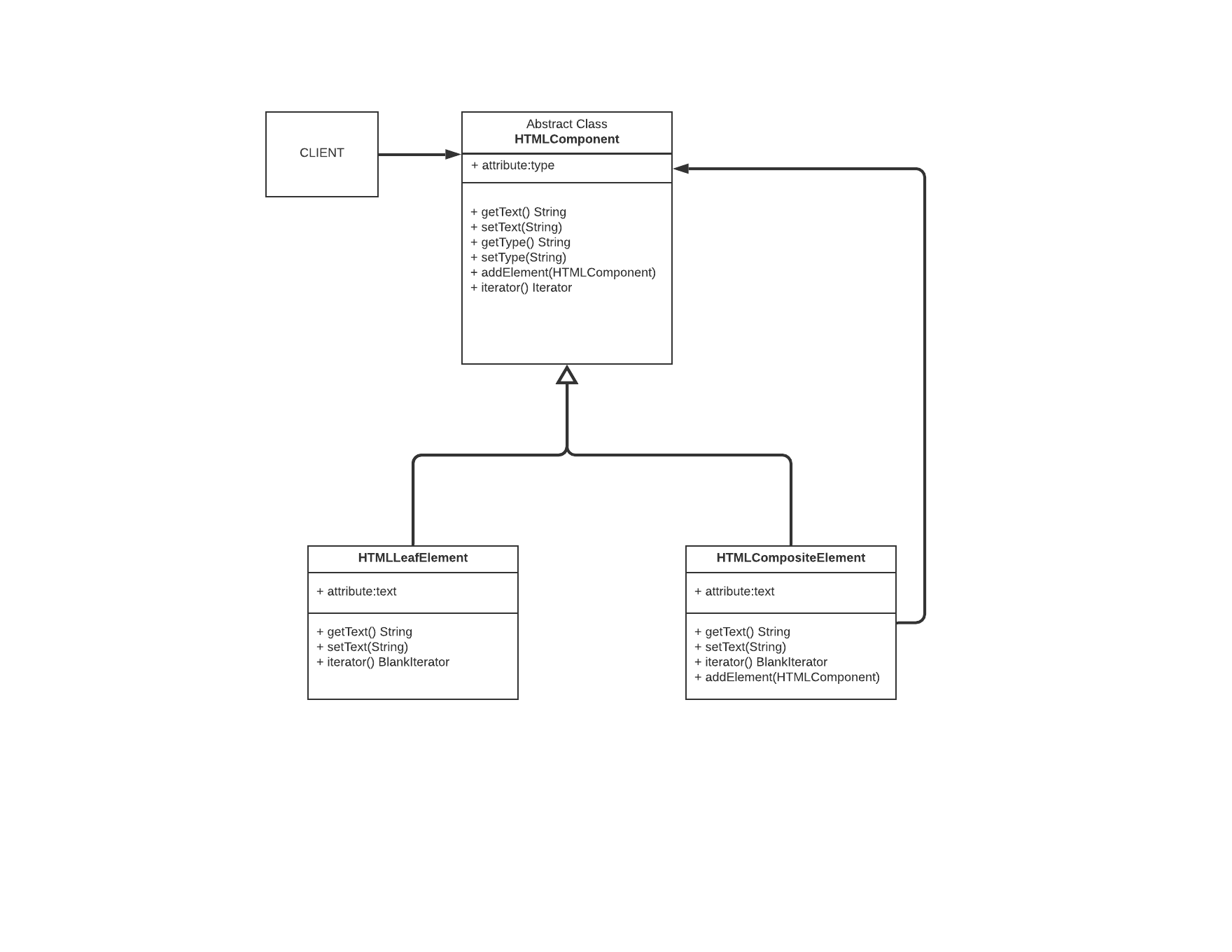
This is our component class, the high level element of an HTML page:
abstract class HTMLComponent {
private String type;
abstract String getText();
abstract void setText(String text);
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public void addElement(HTMLComponent element) {
throw new UnsupportedOperationException("The Element cannot have children nodes.");
}
abstract Iterator<HTMLComponent> iterator();
}
It is being extended by two classes:
- HTMLLeafElement: The class extends
setText,getTextanditerator. ThesetTextandgetTextare pretty obvious but theiterator()return aBlankIteratorobject that makes sure that no elements can be fetched from this leaf element because it returnsfalseevery timehasNext()is called.
class HTMLLeafElement extends HTMLComponent {
private String text;
@Override
public void setText(String text) {
this.text = text;
}
@Override
public String getText() {
return text;
}
public Iterator<HTMLComponent> iterator() {
return new BlankIterator<>();
}
}
- HTMLCompositeElement: This class has the most interesting part. In order to get the text content from the child nodes
it calls the
getText()method of its children iteratively(or recursively?).
class HTMLCompositeElement extends HTMLComponent {
private String text;
@Override
public void setText(String text) {
this.text = text;
}
private List<HTMLComponent> elements = new ArrayList<>();
public void addElement(HTMLComponent element) {
elements.add(element);
}
public Iterator<HTMLComponent> iterator() {
return elements.iterator();
}
public String getText() {
StringBuilder htmlText = new StringBuilder(this.text);
Iterator<HTMLComponent> iter = this.iterator();
while (iter.hasNext()) {
htmlText.append(iter.next().getText());
}
return htmlText.toString();
}
}
This way we can create the following HTML tree:
<div>
<div>
<p>Paragraph 1</p>
<p>Paragraph 2</p>
<p>Paragraph 3</p>
</div>
<div>
<div>
<p>Paragraph 4</p>
<p>Paragraph 5</p>
<p>Paragraph 6</p>
</div>
<p>Paragraph 7</p>
<p>Paragraph 8</p>
</div>
</div>
HTMLLeafElement paragraph1 = new HTMLLeafElement();
paragraph1.setType("p");
paragraph1.setText("Paragraph 1");
HTMLLeafElement paragraph2 = new HTMLLeafElement();
paragraph2.setType("p");
paragraph2.setText("Paragraph 2");
HTMLLeafElement paragraph3 = new HTMLLeafElement();
paragraph3.setType("p");
paragraph3.setText("Paragraph 3");
HTMLCompositeElement div1 = new HTMLCompositeElement();
div1.addElement(paragraph1);
div1.addElement(paragraph2);
div1.addElement(paragraph3);
// some code for div2
HTMLCompositeElement page = new HTMLCompositeElement();
page.addElement(div1);
page.addElement(div2);
As we’ve some context about the Composite Design Pattern, let’s look into the Wikipedia definition for it.
In software engineering, the composite pattern is a partitioning design pattern. The composite pattern describes a group of objects that are treated the same way as a single instance of the same type of object. The intent of a composite is to “compose” objects into tree structures to represent part-whole hierarchies. Implementing the composite pattern lets clients treat individual objects and compositions uniformly.
Real World Example
Let’s look into an open source head less browser, HtmlUnit, and see how they’ve implemented the composite design pattern in their code base from a very high level point of view.
Just like the abstract class, HTMLComponent, we’ve created, there’s an abstract class in HtmlUnit named DomNode.
Then several DOM elements, like, HTMLTextAreaElement or HTMLPictureElement, extend it. These DOM elements are similar to our
HTMLLeafElement and similar to our HTMLCompositeElement there is a class called HtmlPage that holds other DomNodes.
Just like how we’ve handled the getText() method considering the type of the element, there’s a method called
getCanonicalXPath() that has different implementations in both the classes.
For the HtmlPage:
@Override
public String getCanonicalXPath() {
return "/";
}
and, for the HtmlElement:
@Override
public String getCanonicalXPath() {
final DomNode parent = getParentNode();
if (parent.getNodeType() == DOCUMENT_NODE) {
return "/" + getNodeName();
}
return parent.getCanonicalXPath() + '/' + getXPathToken();
}
Use Case Scenarios
- When there is a requirement to represent an entity tree, or a hierarchy of objects.
- When the difference between the composition of the objects and the single object needs to be abstracted out so that the client treats all of them uniformly
I’ve created these tutorials after learning Design Patterns from Head First Design Patterns (A Brain Friendly Guide).
